Posts
-
Uncertainty evaluation - a comparison of different approaches
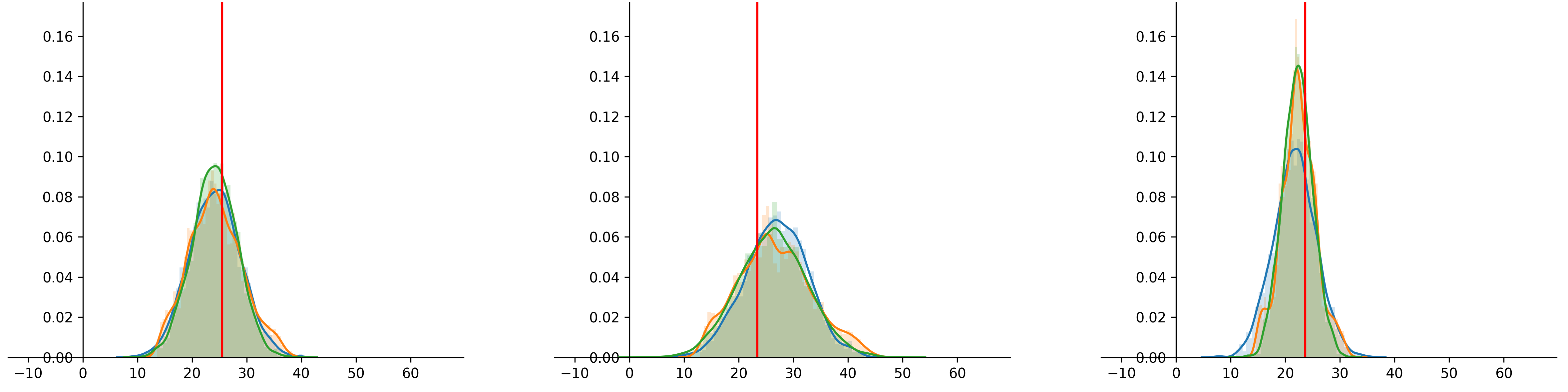
After showing two (frequentist) ways of calculating prediction uncerainty, I wanted to see how they compare to each other, and Baysian approach. But how do you evaluate predicted distributions against single true values? And how do you evaluate the uncertainty itself? In this blog, I would like to compare three different methods, trained on a (slightly) more real-life dataset (boston house-prices [3]) by showing a metric used to evaluate single point predictions, and some plots to evaluate the uncertainty. Let’s get right into it.
-
Prediction uncertainty part 2
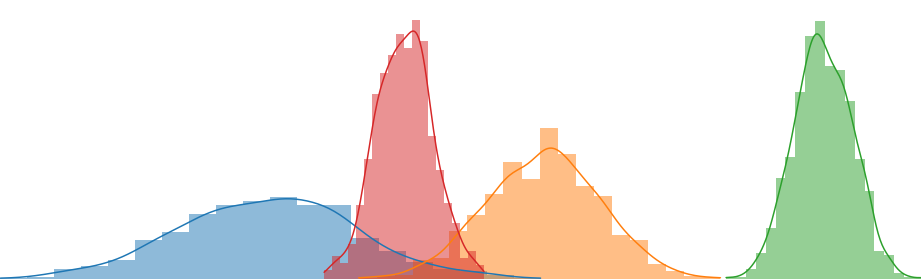
In this post, I would like to continue where I left off in the previous post regarding prediction uncertainty by showing a second frequentist way of calculating uncertainty for regression problems. After fitting the quantiles (aleatoric uncertainty) and sampling using MCDropout (epistemic uncertainty), we combined the sampled distributions in a single distribution. We did this by sampling from each sampled CDF. This CDF however, wasn’t a full distribution but a collection of quantile predictions. In order to sample from it, we used linear interpolation in between the quantile predictions. Nothing wrong with that, but I wanted to see if there was an easier way to combine the distributions into a single predictive posterior distribution. In this blog post I’ll explain another way to calculate and combine aleatoric and epistemic uncertainty. All code used in this blog will be published on Github. In first notebooks you will find a more elaborate explaination of the code. In the next notebooks, as well as in the package, I’ve wrapped the model classes in a SKlearn-like interface. This allows me to create cleaner notebooks in the comparison phase.
-
A frequentist approach to prediction uncertainty
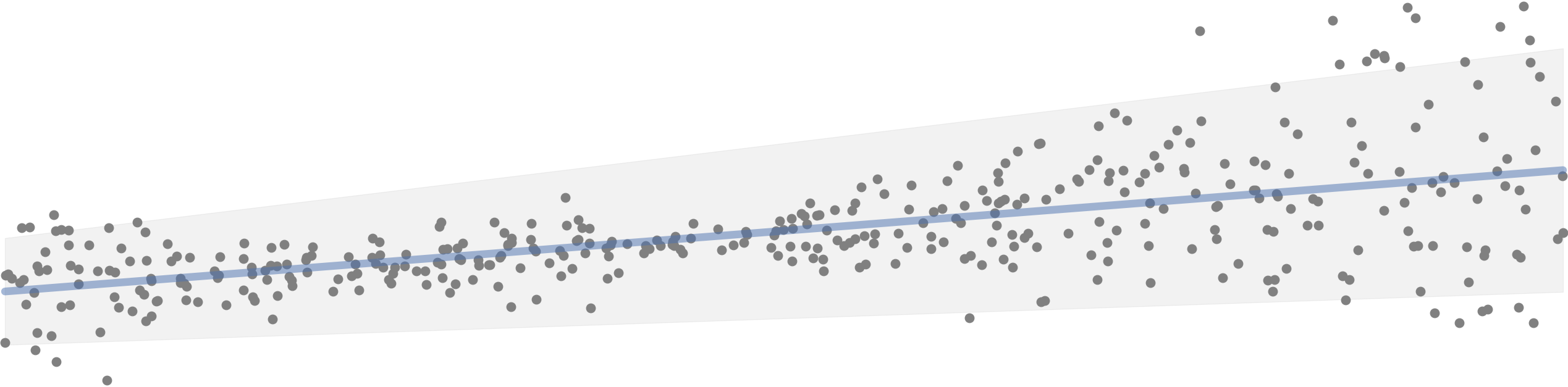
Uncertainty for single predictions becomes more and more important in machine learning and is often a requirement at clients. Especially when the consequenses of a wrong prediction are high, you need to know what the probability (distribution) of an individual prediction is. In order to calculate this, you probably think about using Bayesian methods. But, these methods also have their downsides. For example, it can be computationally expensive when dealing with large amounts of data or lots of parameters. What I didn’t know was that you actually can get similar results using frequentist methods. This post will explain how you can calculate different types of uncertainty for regression problems using quantile regression and Monte Carlo dropout. All code used in this blog will be published on Github.